# 群友问题集
# 为什么云函数执行成功了,前端还是会返回错误呢?
云函数最终返回的数据必须带上 code:0 如:
return {
code: 0,
msg: '添加成功',
};
2
3
4
return {
code: 0,
orderInfo: {},
};
2
3
4
let res = { code: 0, msg: '' };
res.orderInfo = xxxxx1;
res.userInfo = xxxxx2;
return res;
2
3
4
5
6
如果 return 的 code 不为 0,则当错误处理,框架会自动 alert(msg) 如:
return { code: -1, msg: '积分不足' };
return { code: -1, msg: '参数错误' };
建议使用以下云函数模板
'use strict';
module.exports = {
/**
* 此函数名称
* @url user/pub/test1 前端调用的url参数地址
* data 请求参数
* @param {String} params1 参数1
*/
main: async (event) => {
let { data = {}, userInfo, util, filterResponse, originalParam } = event;
let { customUtil, uniID, config, pubFun, vk, db, _ } = util;
let { uid } = data;
let res = { code: 0, msg: '' };
// 业务逻辑开始-----------------------------------------------------------
res.orderInfo = xxxxxxx;
res.userInfo = userInfo;
// 业务逻辑结束-----------------------------------------------------------
return res;
},
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 请求云函数报 403 错误
code=403 为权限不足,通常是因为你写的云函数没有放在 pub 或 kh 目录下导致的
pub目录:任何人都可以请求的云函数
kh目录:只有登录用户才可以请求的云函数
sys目录:登录且拥有对应权限的用户才可以请求的云函数
其他目录:其他目录均为私有目录,不可被前端直接访问
2
3
4
5
# 如何在云函数中访问 http 服务
let requestRes = await vk.request({
url: `https://xxxxxxx.xxxx.com`,
method: 'POST',
data: {
a: 1,
b: {
c: '2',
},
},
useContent: true, // true代表将参数转为使用body请求体
});
2
3
4
5
6
7
8
9
10
11
# 云函数中时区问题导致获取到的本月起始时间和截止时间不准确
// 使用以下api可以解决时区问题:
let commonTime = vk.pubfn.getCommonTime(new Date());
2
# 云函数中如何使用缓存
# 云函数中如何将网络图片上传到云储存
let imageBuffer = await vk.request({
url: 'https://xxxx.xxxx.com/xxx.jpg',
method: 'GET',
dataType: 'default',
});
let uploadFileRes = await uniCloud.uploadFile({
cloudPath: 'test.jpg',
fileContent: imageBuffer,
});
let fileUrl = uploadFileRes.fileID;
2
3
4
5
6
7
8
9
10
# 云函数中如何将网络图片转成 base64
let imageBuffer = await vk.request({
url: 'https://xxxx.xxxx.com/xxx.jpg',
method: 'GET',
dataType: 'default',
});
let base64 = 'data:image/png;base64,' + imageBuffer.toString('base64');
2
3
4
5
6
# 云函数(云对象)中如何调用另一个云函数(云对象)
# 方式一(推荐,vk-unicloud 版本需>=2.9.0)
注意:方式一只支持符合 VK 框架路由规则的云函数或云对象
优势:完美契合 VK 框架,且拥有继承当前用户 token、ip 等功能。
// 云函数内调用其他云函数或云对象内的函数,在同一个router大函数下,name参数可不传
let callRes = await vk.callFunction({
name: 'router',
url: 'client/user/pub/test',
event,
data: {
a: 1,
},
});
console.log(callRes);
// 云对象内调用其他云函数或云对象内的函数,在同一个router大函数下,name参数可不传
let callRes = await vk.callFunction({
name: 'router',
url: 'client/user.test',
clientInfo: this.getClientInfo(),
data: {
a: 1,
},
});
console.log(callRes);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 方式二(此方式适用任何场景)
优势:可以请求不是 vk 框架下的云函数
let callFunctionRes = await uniCloud.callFunction({
name: 'router',
data: {
$url: 'client/user/pub/test',
data: {
a: 1,
b: 2,
},
},
});
console.log(callFunctionRes.result);
2
3
4
5
6
7
8
9
10
11
# 方式三 (此方式需要单独写成公共函数,如 service/user/util/login_log.js)、
优势:减少一次网络请求,性能高
// 下方代码是演示调用 service/user/util/login_log 文件内的 add函数
let loginLogService = vk.require('service/user/util/login_log');
await loginLogService.add(
{
type: 'login',
login_type: 'univerify',
user_id: res.uid,
context: originalParam.context,
},
util
);
2
3
4
5
6
7
8
9
10
11
# 云函数中如何写公共函数,方便代码复用
# 方式一(通过 vk.require 引入的方式)
优势:公共函数的文件可以写在 router 的任意位置
// 下方代码是演示调用 service/client/user/util/util.js 文件内的 test 函数
let userUtil = vk.require('service/client/user/util/util.js');
let testRes = await userUtil.test({
a: 1,
b: '2',
});
console.log('testRes: ', testRes);
2
3
4
5
6
7
# 方式二(通过 vk.myfn.xxx 直接调用公共函数)
优势:不需要 vk.require 引入,使用更方便
公共函数文件地址:router/util/pubFunction.js(固定不可变)
// 下方代码是演示调用 router/util/pubFunction.js 文件内的 test 函数
let testRes = await vk.myfn.test({
a: 1,
b: '2',
});
console.log('testRes: ', testRes);
2
3
4
5
6
# 文件上传成功后如何自动保存到 vk-files 表里?
vk.uploadFile 的参数 needSave 设置为 true 如:
// 选择图片
uni.chooseImage({
count: 1,
sizeType: ['compressed'],
success: (res) => {
vk.uploadFile({
title: '上传中...',
filePath: res.tempFilePaths[0],
file: res.tempFiles[0],
needSave: true,
success: (res) => {
// 上传成功
},
});
},
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
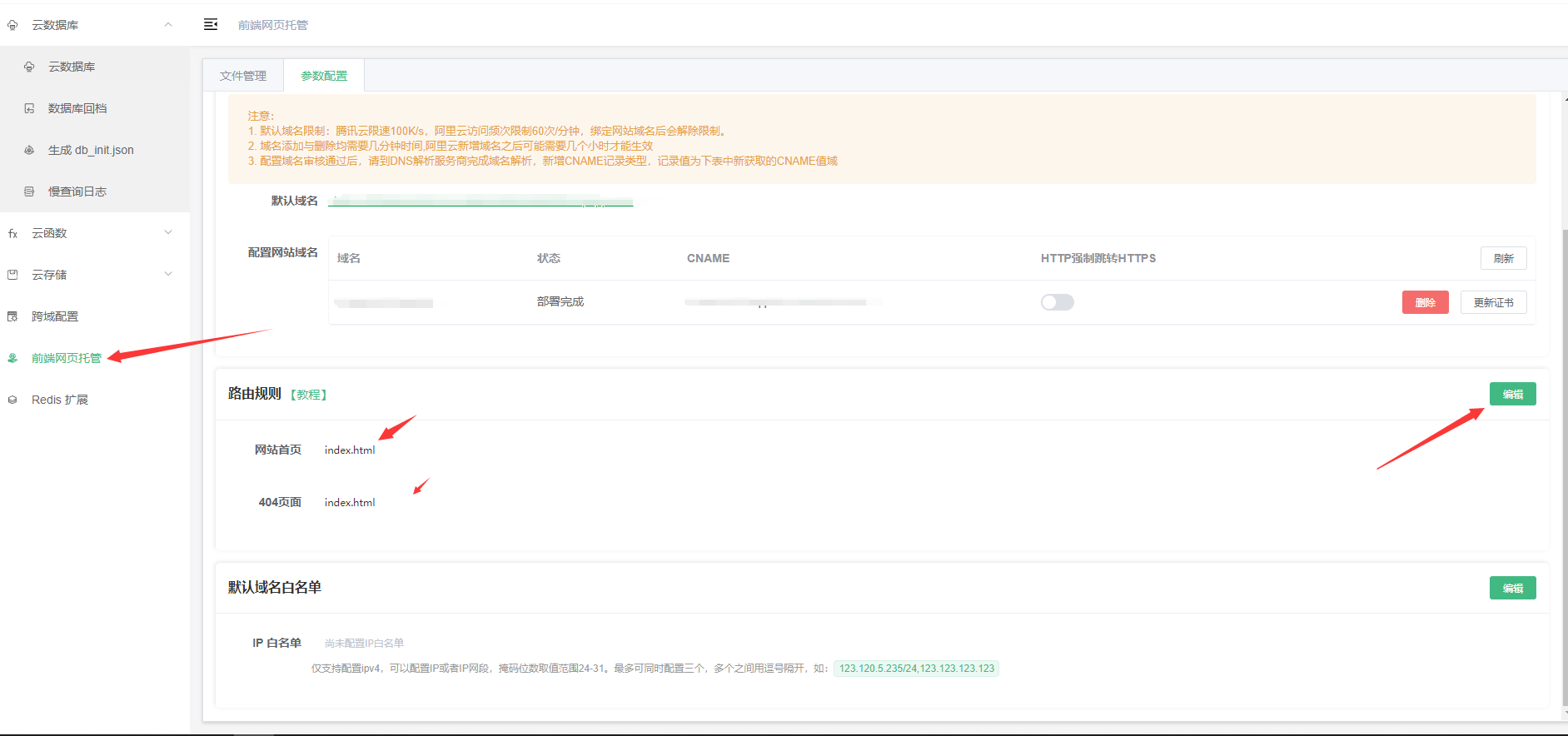
# 为什么前端路由页面刷新报 404 错误,正常跳转可以,刷新报错?
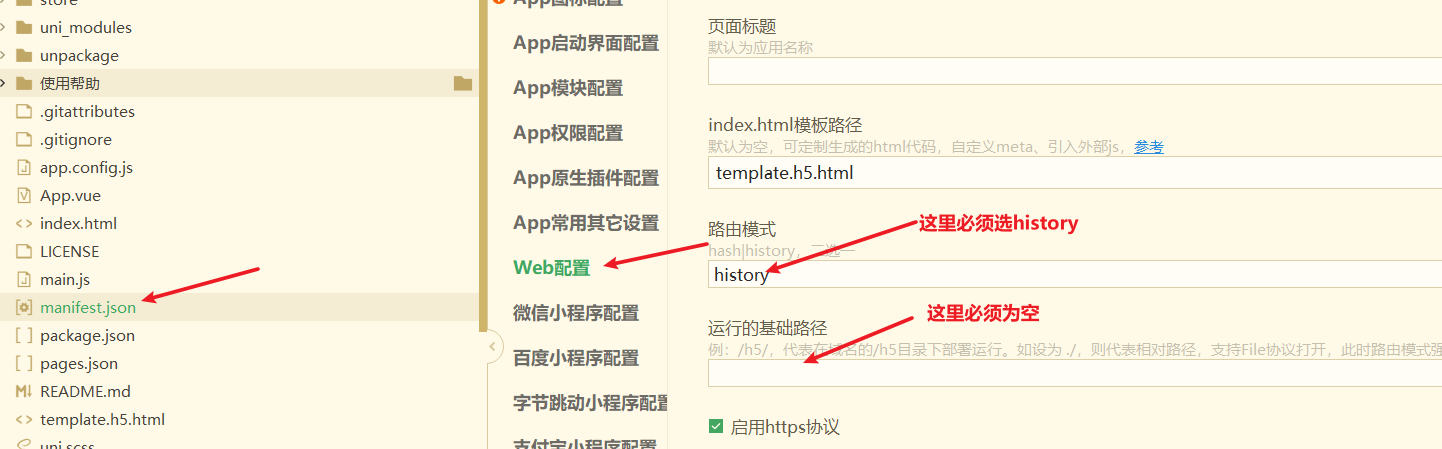
方案一:在 manifest.json 中 H5配置 设置路由模式为 hash
方案二:在 uniCloud 前端网页托管 页面中 点击 参数配置 编辑路由规则 把 网站首页 和 404页面 都设置为 index.html
# 公众号登录流程
- 1、需要登录公众号后台,获取
appid和appsecret并填写在uniCloud/cloudfunctions/common/uni-config-center/uni-id/config.json内
"h5-weixin": {
"oauth": {
"weixin": {
"appid": "微信公众号appid",
"appsecret": "微信公众号appsecret"
}
}
},
2
3
4
5
6
7
8
- 2、在公众号后台左侧菜单 - 设置与开发 - 公众号设置 - 功能设置 - 配置业务域名、网页授权域名、JS 接口安全域名
- 3、运行如下代码,访问授权页面
let appid = '你的公众号appid';
let redirect_uri = window.location.href.split('?')[0];
let scope = 'snsapi_userinfo';
let url = `https://open.weixin.qq.com/connect/oauth2/authorize?appid=${appid}&redirect_uri=${redirect_uri}&response_type=code&scope=${scope}&state=STATE#wechat_redirect`;
window.location.href = url;
2
3
4
5
注意 1:h5 的路由模式必须配置为 history,因为微信公众号登录的回调地址不支持 hash 模式。 注意 2:你的前端托管那需要设置 404 指向的页面为 index.html

- 4、授权完后页面会重新返回到你自己的页面(但此时页面已经刷新了),此时在页面
onLoad函数中可以获取到code - 5、运行如下代码,进行微信公众号登录(其中 this.options 是 onLoad 获取的参数对象)
if (!this.options.code) {
vk.toast('请先获取code');
return false;
}
vk.userCenter.loginByWeixin({
data: {
code: this.options.code,
state: this.options.state,
},
success: (data) => {
// 登录成功后执行的逻辑
vk.alert(JSON.stringify(data));
},
});
2
3
4
5
6
7
8
9
10
11
12
13
14
# 为什么感觉云开发的响应速度比传统服务器开发要慢?
先看一下实际测试数据。
| 项目 | 云开发耗时(单位毫秒) | 传统本地开发耗时(单位毫秒) |
|---|---|---|
| 1 次请求(无数据库简单查询) | 100 | 1 |
| 1 次数据库简单查询耗时 | 80 | 40 |
| 1 次请求(1 次数据库简单查询) | 180 | 41 |
| 1 次请求(3 次数据库简单查询) | 340 | 121 |
| 1 次请求(5 次数据库简单查询) | 500 | 201 |
| 1 次请求(10 次数据库简单查询) | 900 | 401 |
友情提醒:云函数连接云端比连接本地云函数要快(上面的测试是连接云端时的速度)(因为本地云函数连接云开发的数据库是外网访问,但本地的优势是不需要上传,且能实时打印日志)
从测试数据中我们可以看出云开发响应速度确实比传统服务器开发要慢,且至少慢了 1 倍,那么为什么呢?
以 java 为例
传统开发 用户前端请求 - nginx - tomact - mysql 大致为 3 层(如果去掉 nginx,则只有 2 层,甚至 tomact 和 mysql 是在同一台服务器上的)。
而云开发 内部更为复杂,中间环节也比较多,导致耗时长,且云开发是所有人共享整个服务器集群,所以服务器承担的总并发量也是很大的,导致延迟会高。
云厂商如果要将延迟降低,势必要增加服务器集群,增加机房,这些都是成本。所以云厂商会尽量让延迟控制在一个合理的范围内,成本和收益要对等。
# 为什么云函数 URL 化后,明明数据库里有该用户,登录提示用户不存在?
这是因为现在的 uni-id 模块强制不同端用户隔离导致的,你需要在 URL 化的请求头中多传 2 个参数
分别为:
- vk-appid (你项目的 manifest.json 内的 appid)
- vk-platform (运行环境,如 h5、mp-weixin、app-plus 等)
以 jquery 为例
$.ajax({
type: 'POST',
url: 'https://xxx.com/http/router/template/test/pub/test',
headers: {
'content-type': 'application/json;charset=utf8',
'uni-id-token': 'xxxxxxxxx', // 用户token
'vk-appid': '__UNI__89927A9', // 你项目的dcloud_appid
'vk-platform': 'mp-weixin', // 运行环境,如 h5、mp-weixin、app-plus 等
},
data: JSON.stringify({
username: 'test',
password: '123456',
}),
success: (data) => {
console.log('data', data);
},
});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 如何在非 VK 框架目录结构的云函数中使用 VK 框架的 API?
这里的非 VK 框架目录结构的云函数指的是:不是 router 目录结构的云函数。
任意云函数其实都可以通过下面的方式去使用 VK 框架的 API
首先先右键云函数添加依赖,必须勾上的依赖是 uni-config-center 和 vk-unicloud,其他依赖看你自己需求
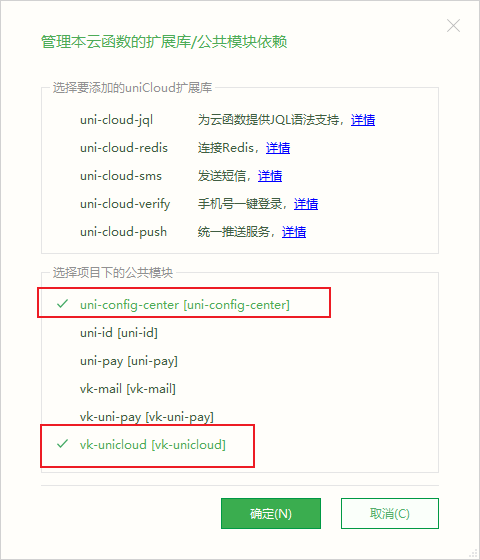
vk 核心库版本>=2.12.0
查看 vk 核心库版本的方法
'use strict';
// 引入 vk-unicloud
const vkCloud = require('vk-unicloud');
// 通过 vkCloud.createInstance 创建 vk 实例
const vk = vkCloud.createInstance({
baseDir: __dirname,
requireFn: require,
});
var db = uniCloud.database(); // 全局数据库引用
var _ = db.command; // 数据库操作符
var $ = _.aggregate; // 聚合查询操作符
exports.main = async (event, context) => {
//event为客户端上传的参数
// 调用 select API
let res = await vk.baseDao.select({
dbName: 'uni-id-users',
pageIndex: 1,
pageSize: 20,
whereJson: {},
fieldJson: {},
sortArr: [{ name: '_id', type: 'desc' }],
});
//返回数据给客户端
return res;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
vk 核心库版本<2.12.0
'use strict';
// 通过 require 引入 vk 实例
const vk = require('vk-unicloud');
// 通过 vk.init 初始化 vk实例(只有初始化后才能使用)
vk.init({
baseDir: __dirname,
requireFn: require,
});
var db = uniCloud.database(); // 全局数据库引用
var _ = db.command; // 数据库操作符
var $ = _.aggregate; // 聚合查询操作符
exports.main = async (event, context) => {
//event为客户端上传的参数
// 调用 select API
let res = await vk.baseDao.select({
dbName: 'uni-id-users',
pageIndex: 1,
pageSize: 20,
whereJson: {},
fieldJson: {},
sortArr: [{ name: '_id', type: 'desc' }],
});
//返回数据给客户端
return res;
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
特别注意:
如果是在 router 云函数内的 js,直接通过 uniCloud.vk 来调用
如果是在 前端js 内,直接通过 uni.vk 来调用
# 小程序加载 uViewUI 后,运行提示代码超 2M,无法预览?
按下图所示: 运行 - 运行到小程序模拟器 - 运行时是否压缩代码(此处打钩即可),打勾后重新编译小程序运行。
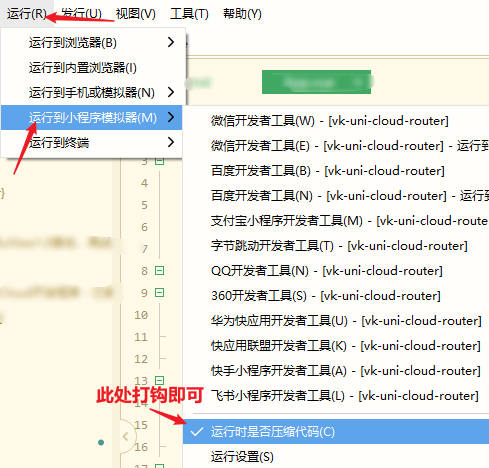
注意:如果这么做后还是超大小,那么你需要将非底部 tabbar 页的其他所有页面写在分包中,不要写主包中,同时图片和字体等静态文件尽量全部用外链。
# 如何请求多服务空间?
# 云函数/云对象如何递归调用自己
当一个云函数实例的资源不能满足需求,或超时时间不够用时。比如要给 10 万个用户发送短信,而短信发送接口一次调用最多支持 50 个手机号码,这样最少需要调用 2000 次接口才能完成;而一个云函数实例完成不了 2000 次接口的调用。这种场景就可以使用云函数递归调用,分解任务实现。
此处以云函数为例,云对象同理
'use strict';
module.exports = {
/**
* 此函数名称
* @url user/pub/test1 前端调用的url参数地址
* data 请求参数
* @param {String} params1 参数1
*/
main: async (event) => {
let { data = {}, userInfo, util, originalParam } = event;
let { customUtil, config, pubFun, vk, db, _ } = util;
let { uid } = data;
// 业务逻辑开始-----------------------------------------------------------
// 执行发短信的逻辑
// 整个逻辑能实现递归要靠id排序来实现,也就是假设我要给10万人要发短信,每次只能发100人,那么要递归调用1000次
// 我得清楚知道第N次执行时要给哪些人发短信
// 原理是通过某个字段排序实现,如 _id 正序排序,那么第一次请求就是获取到了前100人,同时也得到了第100人的 _id是多少
// 那么第二次调用时,就可以用 > _id 来获取第101-200人,同时也得到了第200人的 _id是多少
// 那么第三次调用时,就可以用 > _id 来获取第201-300人,同时也得到了第300人的 _id是多少
// 以此类推,
// 那么第1000次时,就可以用 > _id 来获取第99901-100000人,这样就10万人全发完了
let { before_id } = data; // 获取当前已操作的id
let res = await sendSms(before_id); // 这方法的内部要实现返回最新已操作的id
// 这里不加await
vk.callFunction({
url: 'client/xxxx/xxxxx',
data: {
before_id: res.before_id,
},
});
// 定义休眠函数
const sleep = (ms) => new Promise((resolve) => setTimeout(resolve, ms));
// 强制云函数等待200毫秒,给一个请求发出去的时间
await sleep(200);
return res;
// 业务逻辑结束-----------------------------------------------------------
},
};
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 使用 router 云函数后,并发和执行速度等会不会受影响?
关于执行速度
不受影响,不管你 router 的 service 下有多少个子云函数,每次请求时,只会加载请求的那一个云函数,且加载时间为 1ms 左右,几乎可以忽略。
主要影响你执行速度的是你自己的业务代码执行逻辑,数据库查询次数越多越复杂,耗时越久。
关于云函数为什么比传统开发请求速度慢的问题,点这里 (opens new window)
关于单个大函数的代码体积限制
阿里云
因为阿里云单个函数的代码体积(含 node_modules 和公共模块)只有 10MB,因此不建议使用太大的第三方 npm 包,如果必须使用,可以新建 1 个 router2,前端请求可以通过 vk.callFunction 指定 name 参数来请求 router2 内的子函数
腾讯云
腾讯云单个函数的代码体积(含 node_modules 和公共模块) 有 50MB,一般无需担心单个 router 会超大小,但建议除非必要,否则不太建议使用太大的第三方 npm 包
前端请求可以通过以下方式请求 router2 内的子函数
vk.callFunction({
name: 'router2',
url: '云函数路径',
title: '请求中...',
data: {},
success: (data) => {},
});
2
3
4
5
6
7
云函数内可以通过以下方式请求 router2 内的子函数
// 云函数内调用其他云函数或云对象内的函数,在同一个router大函数下,name参数可不传
let callRes1 = await vk.callFunction({
name: 'router2',
url: 'client/user/pub/test',
event,
data: {
a: 1,
},
});
console.log(callRes1);
// 云对象内调用其他云函数或云对象内的函数,在同一个router大函数下,name参数可不传
let callRes2 = await vk.callFunction({
name: 'router2',
url: 'client/user.test',
clientInfo: this.getClientInfo(),
data: {
a: 1,
},
});
console.log(callRes2);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
关于最大并发量
不受影响,此处分服务商介绍。
阿里云
- 阿里云整个服务空间限制 1000 个实例,也就是不管你新建多少个大的云函数(router1、router2、router3 ... router48(阿里云最多 48 个大的云函数))
- 这 48 个云函数加起来的并发就是 1000
- 同时,阿里云可以设置单实例多并发单实例最多 100,理论最大并发量 1000*100=100000 (10 万)
但数据库也是有并发限制的(也是基于服务空间,跟云函数数量无关)因此实际并发是达不到 10 万的,除非你的请求不连接数据库。因此大部分情况下,还得看数据库的最大连接数。不过阿里云没有写数据库的最大连接数,故暂不确定阿里云的最大性能。但最小性能可以确定为 1000 并发
腾讯云
- 腾讯云限制单个云函数并发量 1000
- 数据库同时连接数 1000
- 云函数实例扩容速度 500 个/分钟(这个很重要,代表无论你云函数并发最大有多少,你这 1 分钟内其实只有 500 并发,也就是秒杀开始,第一分钟只有 500 并发,第二分钟才是 1000 并发)
理论上腾讯云可以通过复制新建多个 router 函数,前端通过随机数请求 router1 或 router2,来增大云函数最大并发量(最大 5000,腾讯云限制 1 个服务空间目前最大 5000),但数据库 1000 同时连接数是固定的(不管你用 vk 的 router 还是官方框架都一样,官方的前端操作数据库也受此限制),所以最终还是得看数据库的并发量。(除非你的请求不需要请求数据库)
划重点:
- 腾讯云云函数,当秒杀开始时,第一分钟其实只有 500 的云函数并发量。(这个跟使用框架无关,是腾讯云底层限制)(官方的前端操作数据库也受此 500 的影响,因为它也是要通过一个隐藏的云函数来调用数据库的)
- 数据库的并发量也很重要,系统是木桶原理,最短板的长度才是实际性能的上限。(这个也跟框架无关,也是底层限制,官方的前端操作数据库也受此影响)
关于云函数的并发介绍
- 1000 并发不代表只能 1000 个人访问
以秒杀为例:
设
- B:云函数最大并发量
- P:你的下单接口平均访问耗时(单位为秒,这里我们假设为 0.5 秒)
- K:你要秒杀的商品库存(单位为个)
- R:有多少人参与秒杀(单位为个)
- X:全部商品秒完的总耗时(单位为秒)
- Y:全部商品秒完,且所有人接收到已秒完的总耗时(单位为秒)(这里我们假设用户非常想要此商品,不抢到不罢休,没有亲眼看到已秒完。则会一直点下单按钮)(实际情况一般用户点个几下还没抢到一般就不会再点了)
X = K / B * P
Y = R / B * P
以 100 万人秒杀 1 千个商品为例。
X = K / B _ P = 1000 / 1000 _ 0.5 = 0.5 秒,即 1 秒不到,商品全部正常秒完。(实际情况因为有冷启动的原因,所以要加个 1-2 秒,故实际会在 5 秒内)
Y = R / B _ P = 1000000 / 1000 _ 0.5 = 500 秒,即 500 秒后,所有人都会知道商品已秒完。也就是每多 2000 人,时间就加 1 秒。
表现的现象
有 1000 人秒到,其他 99 万 9 千人会报错,然后前端拦截报错后提示:当前活动太过火爆,请稍后再试!(当然你也可以直接提示:已秒完)当商品库存为 0 时。提示:已秒完,然后前端把按钮变灰,防止用户一直点,占用云函数并发量
# 更新插件提示 No END header found 错误
如下图所示
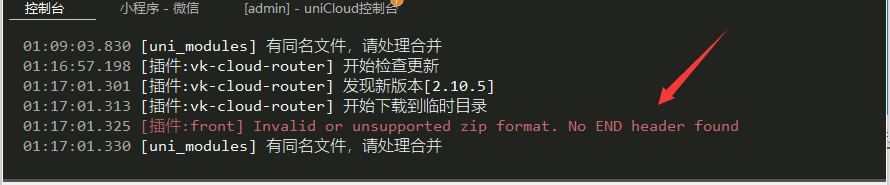
这个错误是 HBX 目前一直存在的问题,手动解决方案:
win 系统
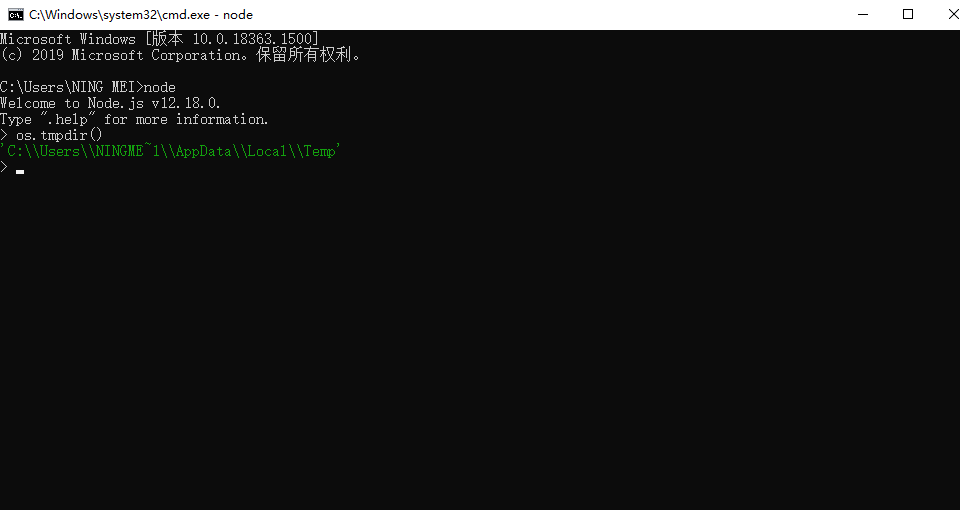
1、进入 CMD 命令窗口,输入
node按回车2、再输入
os.tmpdir()按回车3、可以看到一个目录,比如
C:\Users\NING MEI\AppData\Local\Temp
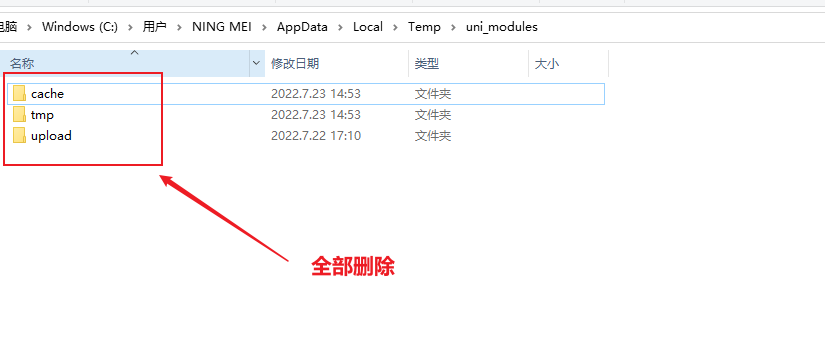
- 4、打开我的电脑,进入这个目录,再此目录找到
uni_modules目录,进入,删除里面所有目录和文件。
- 5、重启 HBX,完成。
mac 系统
也是大概这个逻辑,找到 HBX 的 uni_modules 缓存目录,删除里面的缓存文件即可。(mac 开发者如有空,欢迎补充完这个操作文档)
# 运行项目报 Failed to execute 'open' on 'XMLHttpRequest': Invalid URL
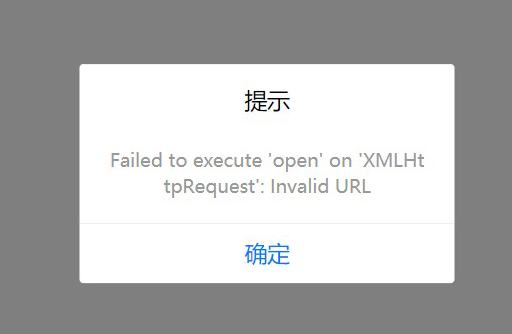
如果你运行项目碰到这个问题,你必须重启 HBX 才能解决,这是 HBX 某个服务奔溃了导致的,如果重启 HBX 还无法解决,则需要重启电脑解决。
# 云函数或云对象如何异步执行一段比较耗时的代码?
可以将需要异步的代码写到云函数 B 中,然后云函数 A 异步调用云函数 B 实现,代码如下
注意:云函数 B 的最大执行时间取决于云函数 B 设置的超时时间,目前腾讯云 30 秒,阿里云 120 秒,支付宝云 180 秒,详见:各云厂商资源限制差异 (opens new window)
云函数
// 请求另外一个云函数
vk.callFunction({
url: '云函数或云对象的请求路径',
event, // 完美契合VK框架,且拥有继承当前用户token、ip等功能。
data: {
a: 1,
},
});
// 等待100毫秒,让请求发出去
await vk.pubfn.sleep(100);
2
3
4
5
6
7
8
9
10
云对象
// 请求另外一个云函数
vk.callFunction({
url: '云函数或云对象的请求路径',
clientInfo: this.getClientInfo(), // 完美契合VK框架,且拥有继承当前用户token、ip等功能。
data: {
a: 1,
},
});
// 等待100毫秒,让请求发出去
await vk.pubfn.sleep(100);
2
3
4
5
6
7
8
9
10
# 如何设置云函数请求超时时间?
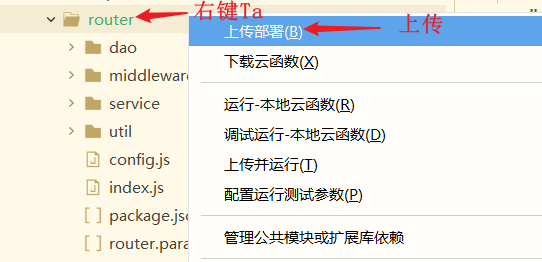
设置最大超时时间
云函数根目录下的 package.json 文件内修改,即 router/package.json,里面的 timeout 代表超时时间(这个超时时间有大小上限),如下图所示。

上限
- 腾讯云:30 秒
- 阿里云:120 秒
- 支付宝云:180 秒
"cloudfunction-config": {
"concurrency": 1,
"memorySize": 512,
"path": "/http/router",
"timeout": 180,
"triggers": [],
"runtime": "Nodejs18",
"keepRunningAfterReturn": false
}
2
3
4
5
6
7
8
9
注意:修改完 router/package.json 需要重新上传云函数才能生效。
前端执行 vk.callFunction 的时候,还可以加一个参数 timeout 来指定本次请求的超时时间,如下
vk.callFunction({
url: '云函数地址',
title: '请求中...',
data: {
a: 1,
b: '2',
},
timeout: 5000, // 单位毫秒,1000 = 1秒
success: (res) => {
console.log('res: ', res);
},
});
2
3
4
5
6
7
8
9
10
11
12
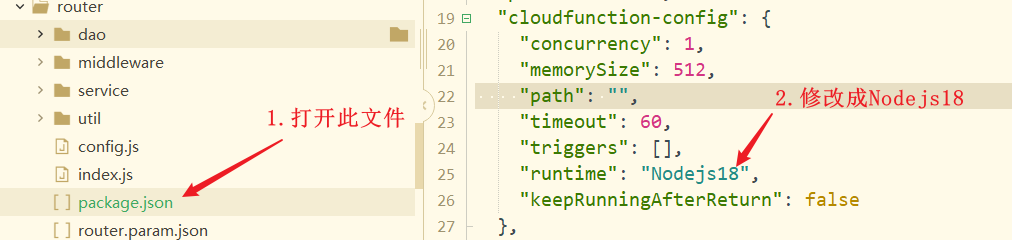
# 如何修改云函数的 node 版本?
云函数根目录下的 package.json 文件内修改,即 router/package.json,里面的 runtime 代表 node 版本,如下图所示。
各云厂商支持的版本如下
| 云厂商 | 默认值 | 可选项 | 推荐值 |
|---|---|---|---|
| 支付宝云 | Nodejs18 | Nodejs16、Nodejs18 | Nodejs18 |
| 阿里云 | Nodejs16 | Nodejs12、Nodejs14、Nodejs16、Nodejs18、Nodejs20 | Nodejs18 |
| 腾讯云 | Nodejs16 | Nodejs12、Nodejs16、Nodejs18 | Nodejs18 |
| 本地运行 | Nodejs18 | Nodejs18 | Nodejs18 |
由于本地运行只支持 Nodejs18,故为了和云端环境一致,因此推荐设置成 Nodejs18
"cloudfunction-config": {
"concurrency": 1,
"memorySize": 512,
"path": "/http/router",
"timeout": 180,
"triggers": [],
"runtime": "Nodejs18",
"keepRunningAfterReturn": false
}
2
3
4
5
6
7
8
9
注意:修改完 router/package.json 需要重新上传云函数才能生效。